导语
本文针对看一看中的假新闻识别做了一个简单先容,从题目定义和业务场景出发,阐述了当前假新闻识别中的一些题目,如标注本钱高和识别的时间泛化等。基于微信看一看的业务特点,创造性提出了基于用户举报数据的弱监视强化学习识别框架-WeFEND,核心算法“Weak Supervision for Fake News Detection via Reinforcement Learning”被AAAI2020会议接收。
一、背景先容
虚假新闻对用户体验影响比较大,有效快捷的假新闻识别是看一看文章质量的重要保障。传统的假新闻识别方法主要是建立事实校验库和对文本语义的深度学习识别,前者需要置信的权威机构和繁琐的人力,后者标注样本的获取费时费力,而且只能捕捉固定时间窗口的假新闻,不具备时间泛化性。比如最近爆发的疫情相关的假新闻,传统的深度学习模型在没有相关信息的情况下是难以有效识别的。
二、总体框架
基于已存在的题目,我们提出了一种基于用户举报数据的弱监视强化学习假新闻识别框架-WeFEND。能够利用用户的举报内收留扩充高时效性的样本识别假新闻,进步假新闻识别的效果。识别框架主要由三部分组成:1)弱监视样本标注器;2)强化学习选择器; 3)假新闻识别器。根据用户举报内收留数据对未标注的数据进行弱监视标注,然后使用强化学习构建的选择器从弱监视标注数据中筛选出能进步假新闻识别效果的高质量的样本,最后对文章进行假新闻识别。如下图所示:
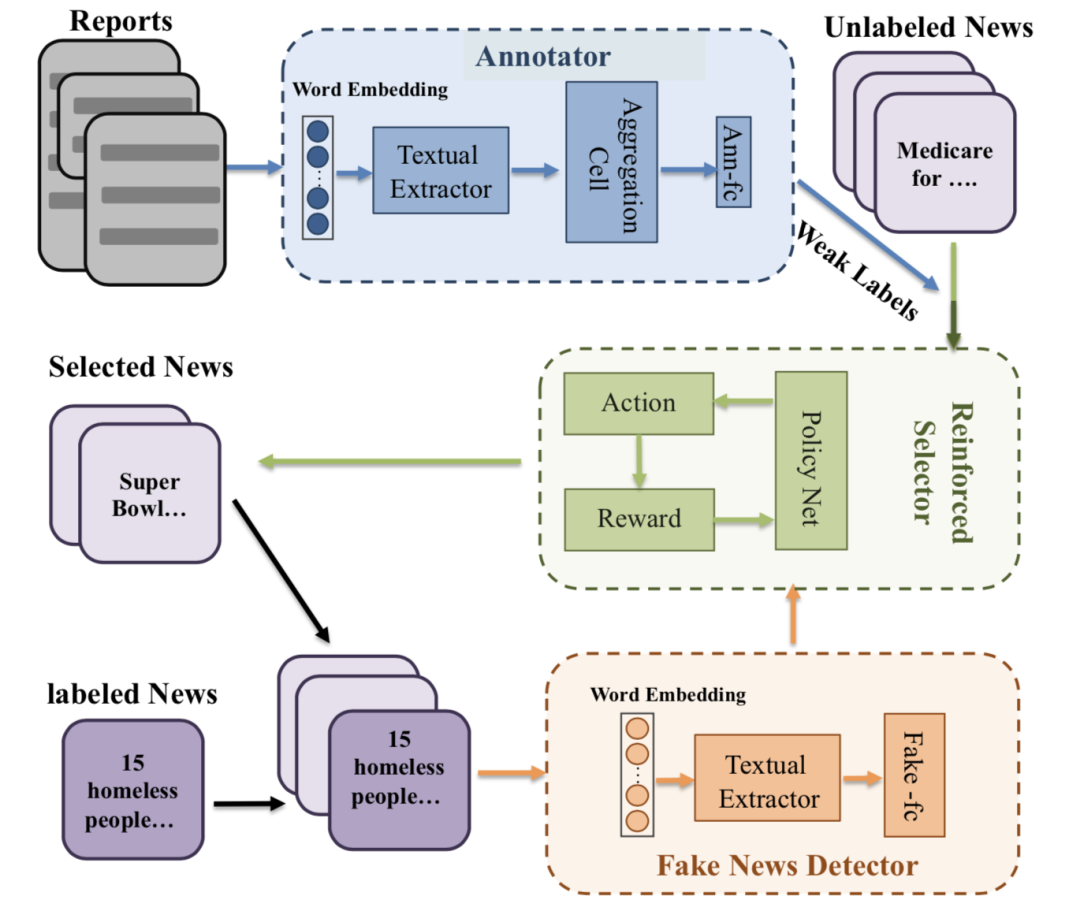
强化学习假新闻识别框架
2.1 弱标签标注器
微信看一看文章有很多用户反馈渠道,我们拿到用户举报为假新闻的文章和对应的举报内收留。首先,通过CNN/LSTM提取用户举报的隐层文本特征表示hjih^i_jhji,而一篇文章对应多个举报,所以我们在初始阶段需要把多个举报内收留进行聚合。由于举报数据的排列不变性,我们使用向量均匀聚合多个举报数据,通过一个全连接网络输出举报内收留的假新闻识别结果,将该结果作为假新闻弱标签。RiR^iRi表示第i个样本的举报数据集聚合,转换如下:
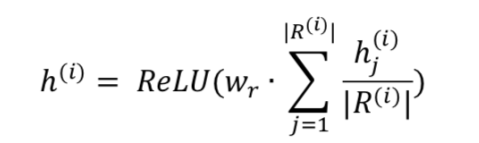
转换结果输出到全连接层Ann-fc,输出假新闻识别概率Dr(Ri,θr)D_r(R^i,θ_r)Dr(Ri,θr)。损失函数定义如下:
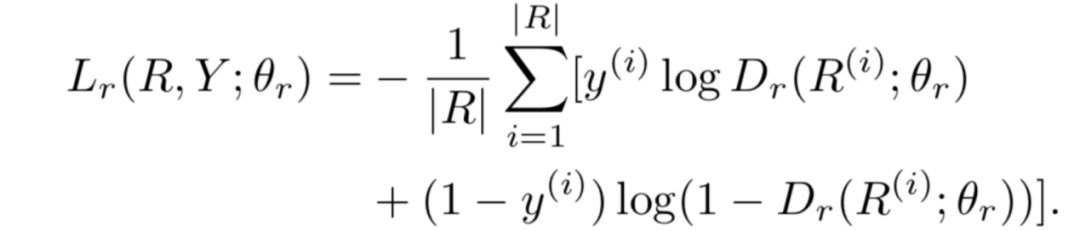
通过举报数据构建的假新闻分类器,对未标注数据进行弱标签标注,获得的结果作为下面的强化学习选择器的输进。
2.2 强化学习选择器
强化学习选择器的目标是通过假新闻识别效果是否有提升来判定是否需要把某一个样本选择出来。对于每一个样本,动作(action)有两种:保存或者移除该样本;当前样本xikx^k_ixik的决策是根据当前的状态和所有历史样本{x1k,x2k,...,xi−1kx^k_1,x^k_2,...,x^k_{i-1}x1k, x2k,...,xi−1k}的决策,该过程符合马尔可夫决策过程(MDP),这也是强化学习的一个先决条件。下面主要来先容一下强化学习选择器的state、action和reward。
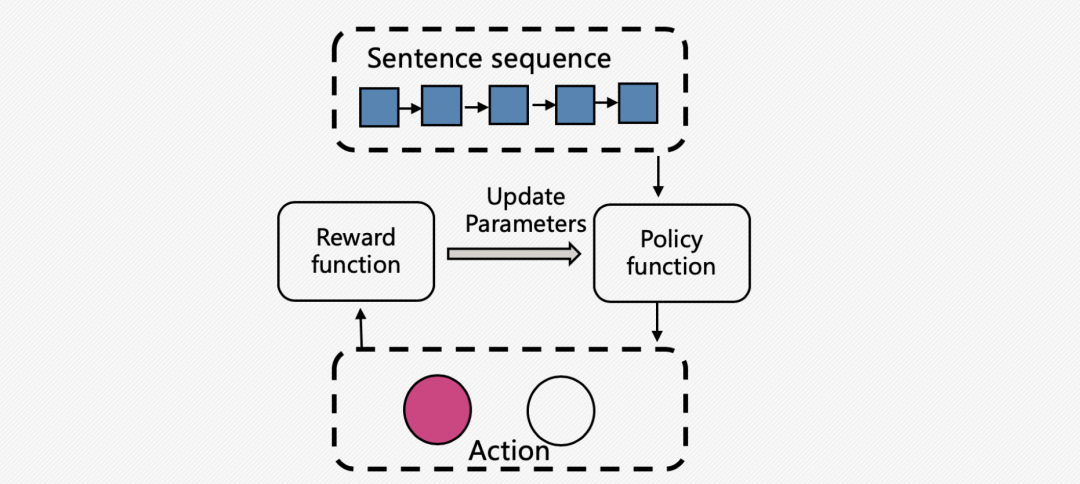
强化学习选择器
2.2.1 状态表示
首先我们先容一下状态state的表示,主要由两部分组成:当前样本的状态表示和历史已选择样本的状态表示,后者是通过所有历史选择样本做一个向量均匀而天生。而每一个状态表示由四个小部分组成:
1、弱标签分类器的输出概率;
2、假新闻分类器的输出概率;
3、当前样本和已选择历史样本的最大余弦间隔;
4、当前样本的弱标签。
这样设计state的目的主要是可以兼顾选择的数据的质量和多样性,前面两个概率输出可以保证筛选数据的质量;而最大化间隔保证选择数据的多样性,确保当前要选择的数据跟历史已选择的差别足够大;弱标签的加进可以平衡种别的分布。
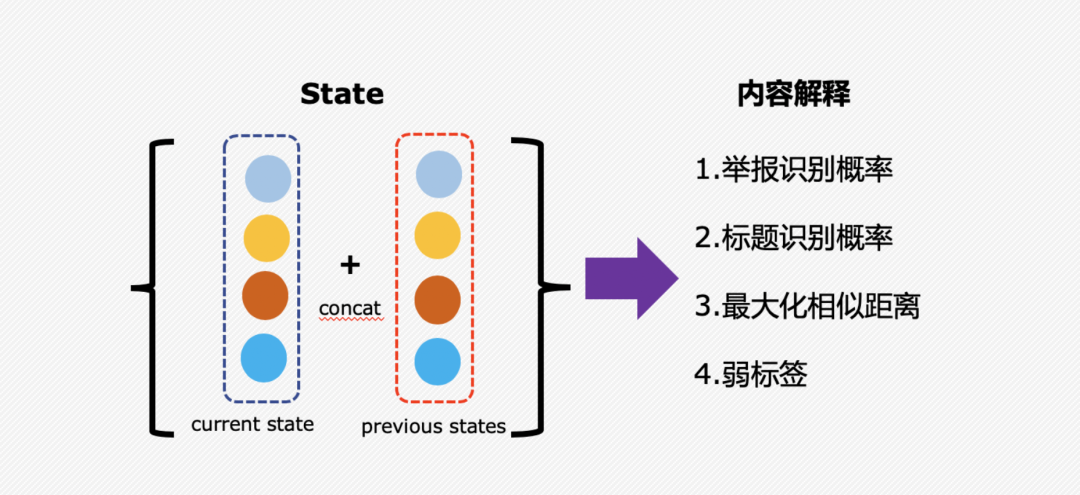
强化学习State表示
2.2.2 动作
强化学习样本选择器这边的动作aika_i^kaik取值空间有两个,1表示保存这个样本,0表示移除这个样本。决策函数(policy function)使用两层全连接网络,使用样本xikx^k_ixik的state表示siks^k_isik作为输进,输出保存该样本的概率。
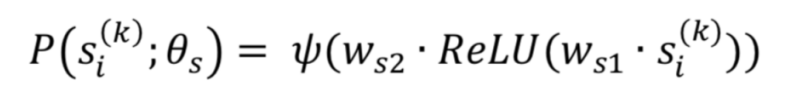
(PS: 为了使给选择器提供更多的反馈并进步练习强化学习过程的效率,我们一开始会让样天职成B份,第k份表示成XkX^kXk,所以本文中的k是表示第k份)
2.2.3 奖励
通过假新闻识别效果的提升我们来判定是否需要保存或者移除当前样本。从标注数据集中我们选择出一部分数据作为验证集,计算验证集合的正确率acc作为baseline。当新的样本通过强化学习选择器选择出来之后我们会重新练习假新闻识别模型,并在验证集上得到新的正确率acckacc_kacck,两者之间的差异就是奖励值RkR_kRk(Reward)。
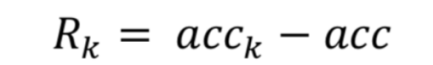
目标是最大化期看的奖励值,对应的目标函数定义和梯度计算如下:
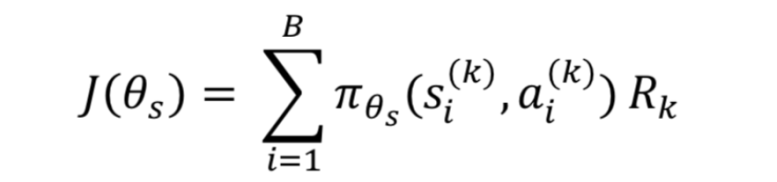
2.3 假新闻分类器
假新闻分类器主要是通过CNN/LSTM提取出的文本特征表示输进到一个全链接层Fake-fc,得到假新闻识别的概率。强化学习选择器选择出的样本集合{Xs,YsX_s, Y_sXs,Ys}和人工标注的样本集合{X,Y}组合一起放进到假新闻分类器中,对应的终极loss可以表示成:
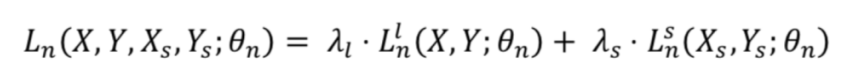
三、实验
我们从微信看一看线上采集了2w+有举报内收留的未标注数据,使用有限可标注的4000+数据往评估假新闻识别框架WeFEND的有效性。为了验证模型的时间泛化性,未标注的数据和标注的数据时间窗口是没有交集的。数据情况如下:
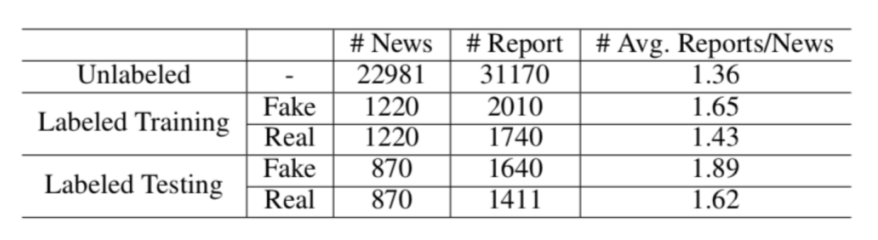
数据集情况
在监视学习方面,我们对比了传统的机器学习方法(LR,RF,SVM)和近期最新提出的深度学习假新闻识别方案CNN, LSTM,EANN(多模态事件对抗模型);在半监视学习方面,我们使用lstm和cnn扩展样本量,加我们的模型中;此外,为了表明强化学习选择器的效果,WeFEND−是没有强化学习选择器的的模型。从图中可以看出,WeFEND−相比于其他模型召回提升明显,但是正确率会有所下降,由于没有通过强化学习选择器,直接弱标签加进的数据噪声比较大,而通过选择器筛选出高质量样本后进行练习的WeFEND,准召都提升到了最优。
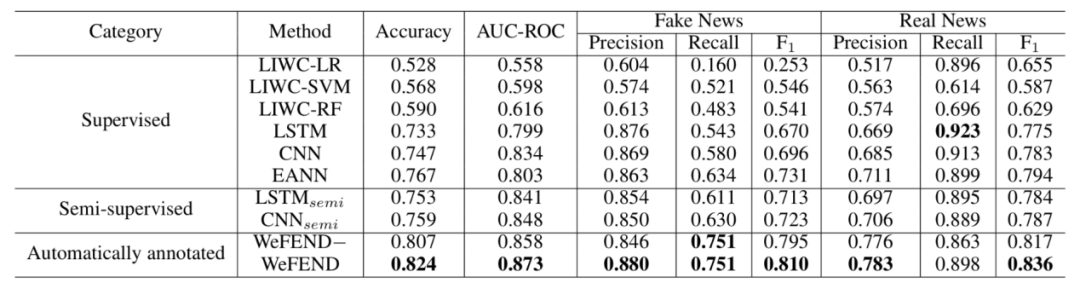
猜测效果对比
四、分析
本节主要分析两个题目:
1、假新闻的分布是否随着时间变化而变化?
2、为什么使用举报数据给假新闻打上弱标签?
我们使用两个时间段的数据(包含标题和举报内收留),将第一阶段采集的标注数据分为两部分,80%切分为练习集DtD_tDt,剩下的20%作为测试集DsD_sDs;再从两个月后标注的数据中取出跟DsD_sDs差未几数目的数据DdD_dDd。使用DtD_tDt练习CNN得到假新闻识别模型,测试在DsD_sDs和DdD_dDd上的效果,下图是使用t-SNE对隐层特征可视化的结果对比:
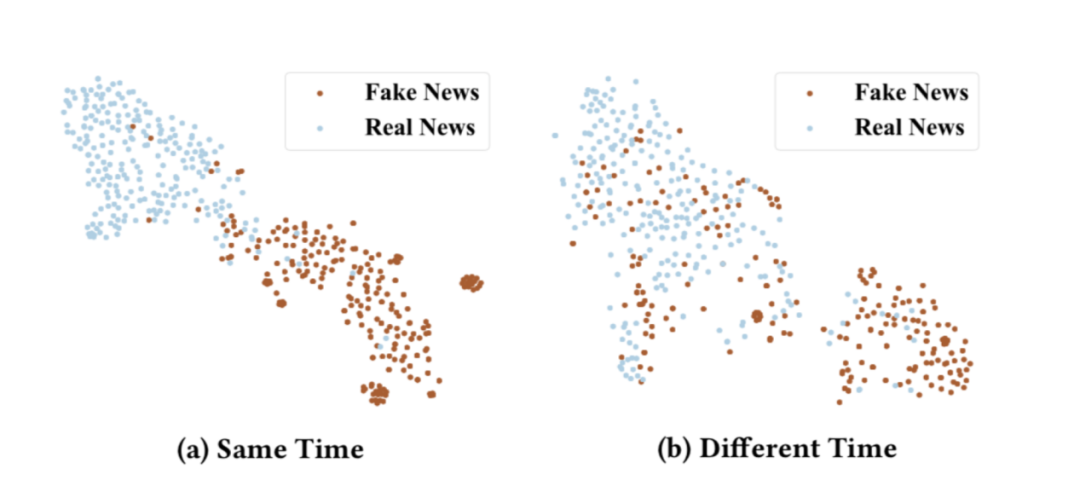
不同时期的假新闻向量化表示对比
从中可以看出,同一时期的假新闻是轻易区分的,而两个月后的数据是向量化表示已经是难以区分了,说明假新闻的分布是随着时间变化的。由于假新闻不中断的变化,我们的模型需要自动捕捉到这些变化的内收留,这也是我们使用举报数据进行弱监视自动标注的原因。使用上面提到的同样的数据集,根据举报内收留我们练习了弱标签分类器,t-SNE的可视化效果如下:
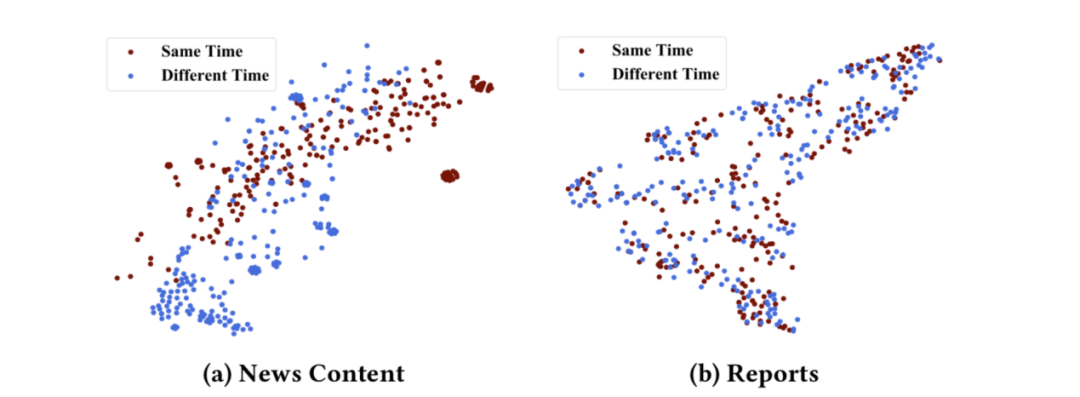
不同时期的假新闻标题和举报向量化表示对比
从上图可以看出,随着时间的变化,假新闻标题会越来越难以区分,但是举报内收留的分布没有随着时间的变化而变化,举报内收留的时间分布不变性让它可以很好对新的假新闻打上弱标签。
五、总结沉淀
针对假新闻的检测出现的标注本钱过高和模型识别时间泛化性题目,我们提出的基于举报数据的强化学习弱监视方案能够对假新闻进行自动而高效的筛选,依托于举报数据的时间不变性,使模型能够及时的捕捉不中断涌现的新的假新闻。
假新闻的识别融合了用户的负反馈信息和本身的文本语义,通过用户反馈信息这种新的知识的引进,辅助我们更高效的判定,类似解决题目的思路对其他业务其他质量的场景也有很大的通用性。质量解决题目的过程是跟黑产不中断对抗的过程,新的质量类型层出不穷,依靠于有限的资源和能力往解决无穷的题目是非常困难的,通过持续的交互构建高效自动化且快速效应的识别能力才是解决之道。
微信AI
不描摹技术的酷炫,不依靠拟人的形态,微信AI是什么?是悄无声息却无处不在,是用技术创造更高效率,是更懂你。
微信AI关注语音识别与合成、自然语言处理、计算机视觉、产业级推荐系统等领域,成果对内应用于微信翻译、微信视频号、微信看一看等业务,对外服务王者荣耀、QQ音乐等产品。












